
使用日志服务Jupyter Notebook扩展¶
背景¶
IPython/Jupyter很流行¶
Jupyter的前身是IPython Notebook,而IPython Notebook的前身是IPython。如下可以看到起发展轨迹:

image
IPython/Jupyter非常流行,从三个方面可以看到: * 数据科学领域Python愈来愈流行已经是既定事实,根据数据科学与机器学习社区Kaggle 2018年调查,超过92%的人员会使用Python,而IPython/Jupyter也已经是不争的Python科学生态入口,使用Python做数据分析的人都会选择IPython/Jupyter作为工具平台。 * IPython/Jupyter Notebook不只是Python独有,作为开放平台,已经支持超过50种语言,例如Go、Java等。 * 各大云厂商都提供了对于Notebook的支持,SaaS生态中也有许多Notebook的有用工具,例如Github、NBViewer等。

image
日志服务对IPython/Jupyter支持¶
阿里云的日志服务(log service)是针对日志类数据的一站式服务,无需开发就能快捷完成海量日志数据的采集、消费、投递以及查询分析等功能。通过日志服务对IPython/Jupyter扩展的支持,可以轻松地使用Python对海量数据进行深度加工(ETL)、交互式分析(通过SQL、DataFrame)、机器学习与可视化等:
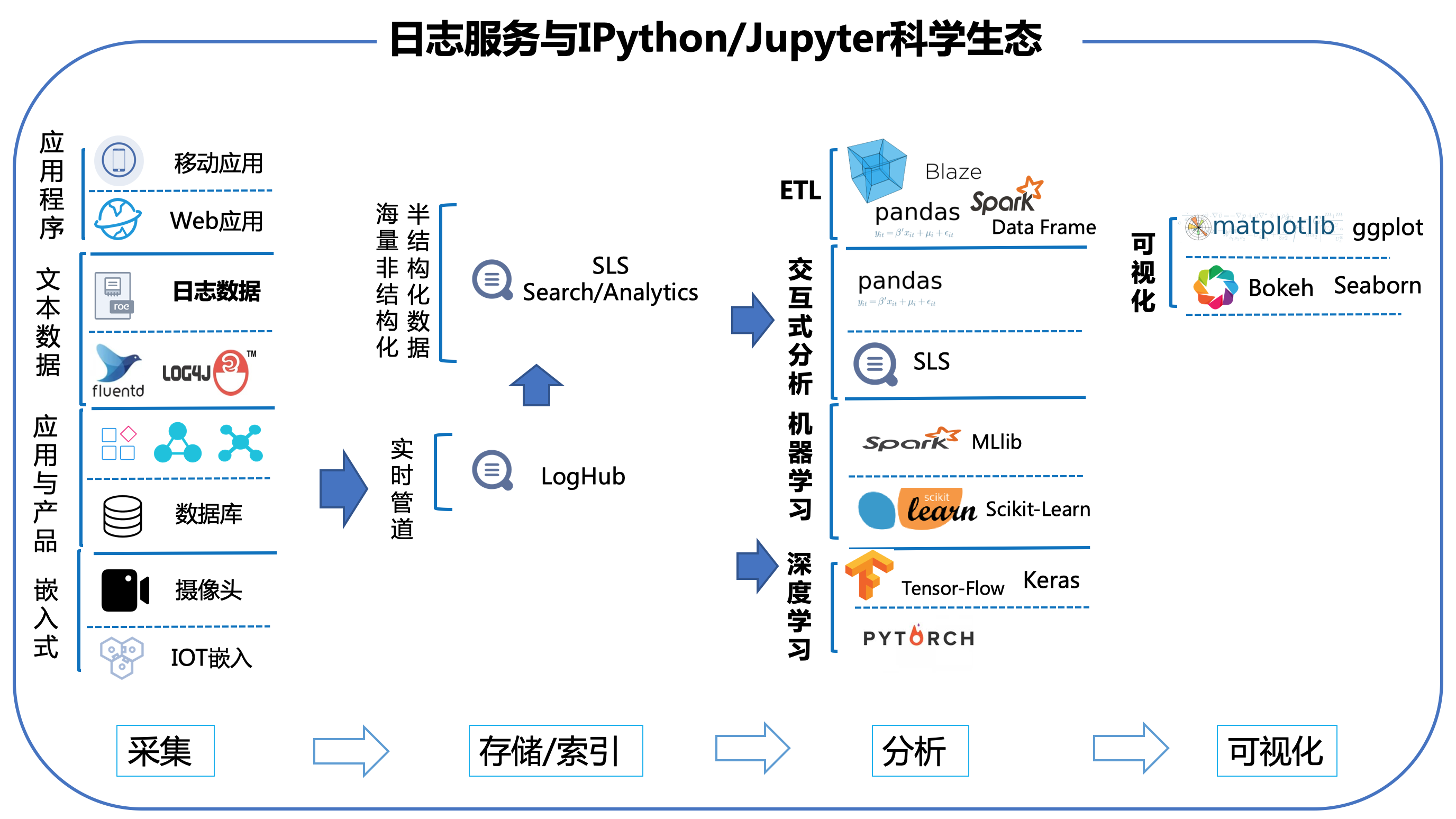
image
功能概述¶
安装¶
快速安装¶
Jupyter Notebook:
1. pip install aliyun-log-python-sdk>=0.6.43 pandas odps ipywidgets -U
配置DataFrame增强交互的配置(仅适用于Notebook):
1. jupyter --path
进入data的第一个目录(或者第二个也可以),
例如C:\Users\Administrator\AppData\Roaming\jupyter
在里面构建一个子目录(如果没有的话):nbextensions
2. python -c "import odps;print(odps);"
根据输出找到odps模块所在目录,进入子目录static > ui ,例如:C:\ProgramData\Anaconda3\Lib\site-packages\odps\static\ui
3. 复制#2中的target目录到#1中,并修改target目录为pyodps
例如: C:\ProgramData\Anaconda3\Lib\site-packages\odps\static\ui\target ==> C:\Users\Administrator\AppData\Roaming\jupyter\nbextensions\pyodps
4. 启动Jupyter前验证下
jupyter nbextension enable --py --sys-prefix widgetsnbextension
jupyter nbextension enable pyodps/main
IPython Shell/Jupyter Lab:
1. pip install aliyun-log-python-sdk>=0.6.43 pandas -U
配置¶

img
加载magic命令
%load_ext aliyun.log.ext.jupyter_magic
配置参数如下:
%manage_log <服务入口> <秘钥ID> <秘钥值> <日志项目名> <日志库名>
在Jupyter Notebook下,也可以无参数传入,通过GUI配置:
%manage_log
关于服务入口、秘钥等,可以进一步参考配置。
配置保存位置¶
以上操作将存储AK、Endpoint、Project、Logstore在~/.aliyunlogcli,
使用的块名是__jupyter_magic__
[__jupyter_magic__]
access-id=
access-key=
region-endpoint=
project=
logstore=
支持场景¶
1. 查询与统计¶

一般查询域统计(配置时间)¶
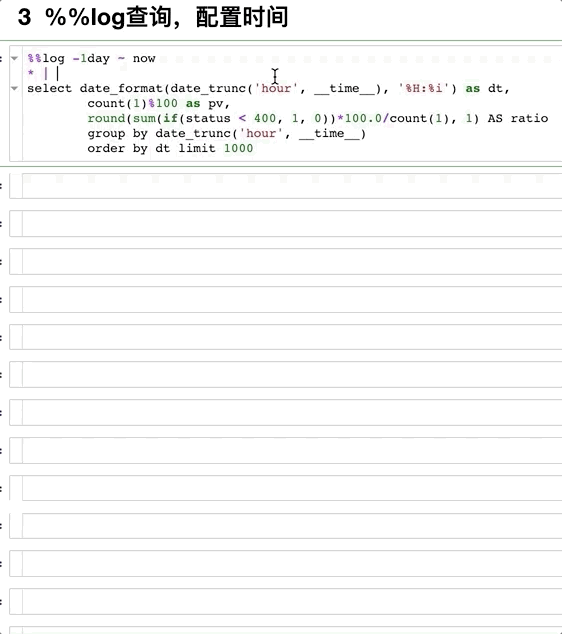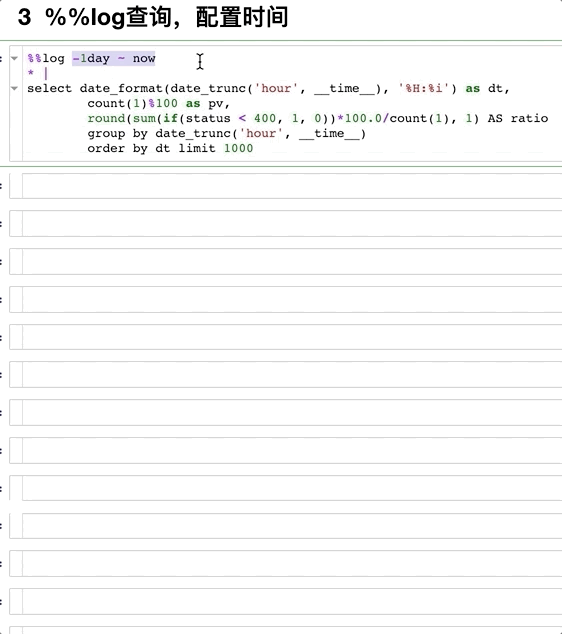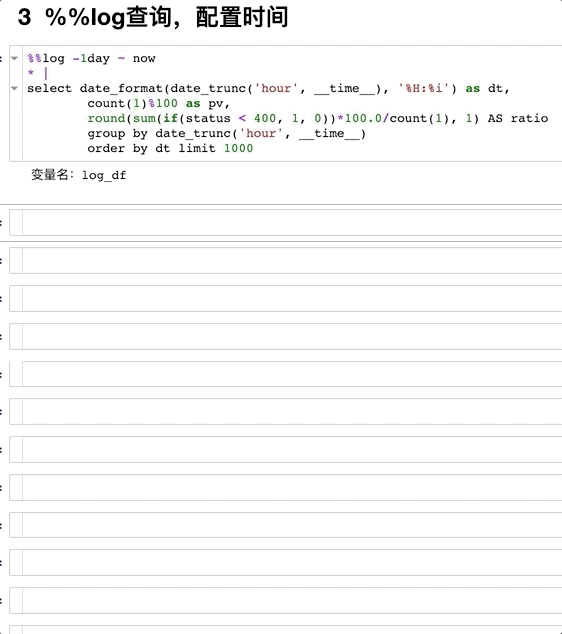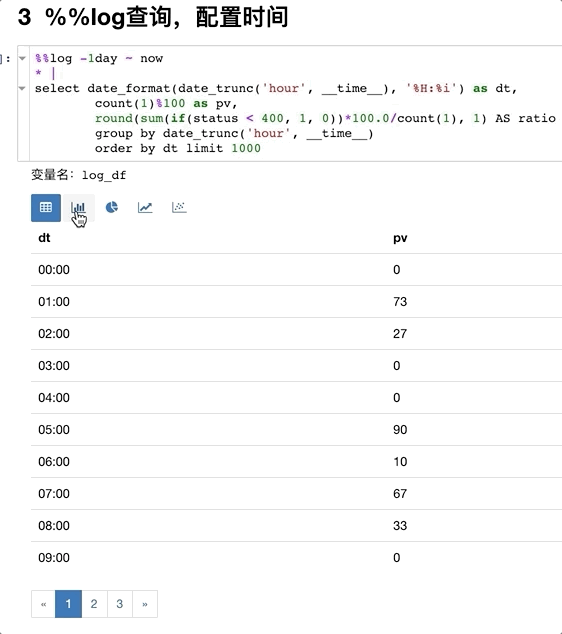
img
第一行用from_time ~ to_time这样的格式操作。 注意:
两个%
%%log -1day ~ now
* |
select date_format(date_trunc('hour', __time__), '%H:%i') as dt,
count(1)%100 as pv,
round(sum(if(status < 400, 1, 0))*100.0/count(1), 1) AS ratio
group by date_trunc('hour', __time__)
order by dt limit 1000
Note:如果只有查询的部分,会自动拉取时间范围内所有日志(自动分页)
具体时间格式的支持,可以参考这里。
2. 全量数据拉取¶
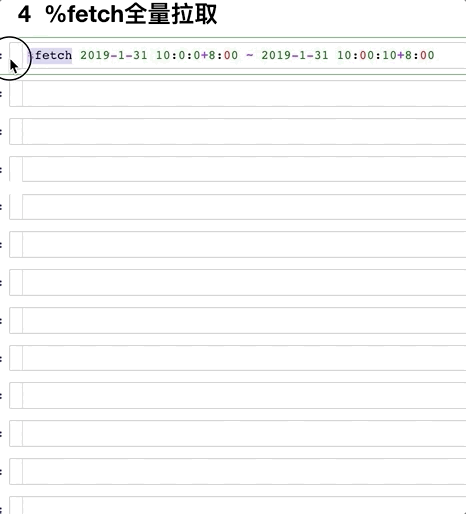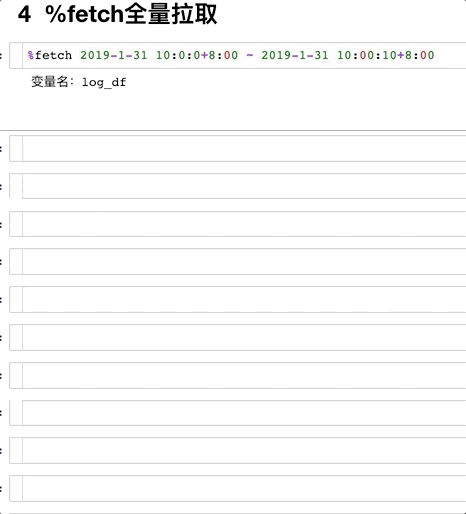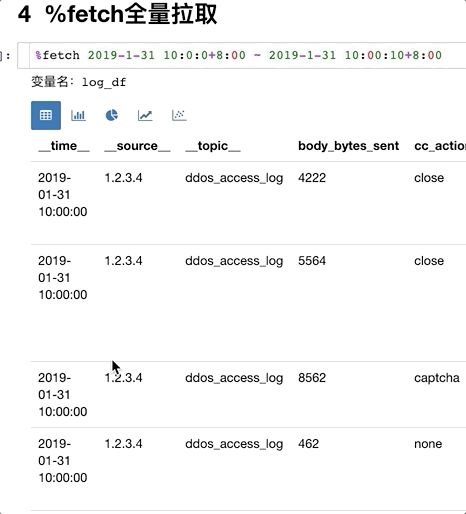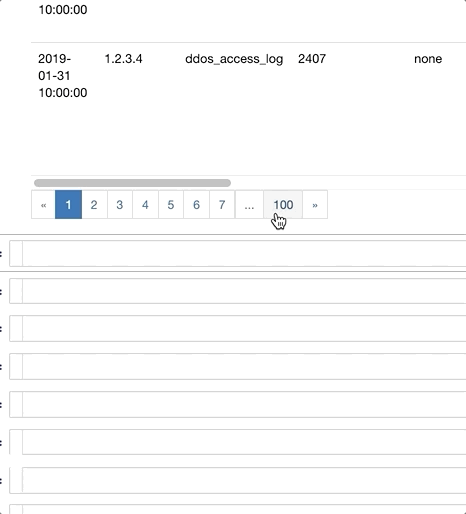
img
如果原始数据没有索引,无法使用查询统计时,或者不需要条件过滤时,可以使用拉取命令。
%fetch 2019-1-31 10:0:0+8:00 ~ 2019-1-31 10:00:10+8:00
Note:
- 时间范围是服务器接受日志的时间,不同于日志自身的时间。
- 拉取过程中,取消的话,已经拉取的数据会放到
log_df_part中。
3. Dataframe操作¶

img
查询返回值通过log_df进行操作。是一个Pandas的标准DataFrame
操作示例:
关于DataFrame操作,可以参考Pandas DataFrame。
注意事项¶
- 魔法命令不支持注释
因框架限制,魔法命令不支持注释(例如下面这种),推荐使用新的单元格放注释。
# count PV for host
%%log -1 day ~ now
* | select host, count(1) as pv group by host